
Full Stack Deep Learning 강의를 듣고 정리한 내용입니다.
Common Data Management Path for Deep Learning
- 딥러닝 과정 중에는 가지고 있는 데이터를 GPU 옆의 local filesystem에 옮기는 작업이 필요하다. 데이터를 train가능한 형태로 옮기는 방법은 프로젝트나 회사마다 다르다. 예를 들면:
- train your images on ImageNet, and all the images are just S3 URLs -> simply download them over to the local filesystem.
- a bunch of text files -> use Spark to process them on a cluster and Pandas data frame to analyze/select subsets that will be used in the local filesystem.
- collect logs and records from your database into a data lake/warehouse (like Snowflake) -> process that output and convert them into a trainable format.
- Key Points in Data Management
- Let the Data flow through you
- Spend a lot of time exploring the dataset.
- Data is the best way to improve your overall ML project
- adding more data & augumenting the existing dataset is better than trying new architectures.
- Keep it Simple Stupid
- Do not over-complicate things!
- Let the Data flow through you
Data Sources
- Where do the training data come from?
- 대부분의 딥러닝 프로젝트에서 labeled data를 요구함.
- (예외: 강화학습, GANs, GPT-3)
- 이미 publicly labeled된 dataset을 사용할 수도 있겠지만 이를 딱히 경쟁력있는 단점은 없음.
- 그래서 많은 회사들이 자신이 가진 데이터를 labeling하는 데 많은 시간과 돈을 투자함.
- Data Flywheel
- user들을 label과정에 참여시킴.
- if you can get your models in front of the users, you can build your products in a mechanism that your users contribute good data back to you and improve the model predictions.
- Semi-Supervised Learning

- data의 일부를 가지고 automatically label.
- online fashion(처음부터 사람이 아예 개입하지 않고 데이터 labeling 진행 가능)
- text
- SEER
- Vision에 적용한 Semi-Supervised Learning
- by FacebookAI
- Trained on 1B random images
- Open Source library
- Image Data Augmentation
- Must do for training vision models
- Frameworks에서 augmentation을 제공함.(e.g.torchvision)
- Done in parallel to GPU training on the CPU
- Other data augmentation
- Tabular
- Delete some cells to simulate missing data
- Text
- replace words or order of things(but not well established)
- Speech/Video
- crop out parts, shrink/grow the timeline, inject noise, mask at different frequencies
- Tabular
Data Storage
- Filesystem
- Foundational layer of stroage.
- Fundamental unit is a "file".(can be text or binary)
- Can be:
- locally mounted
- networked
- distributed
- Fastest option when it comes to storage
- Local Data Format
- binary data: just files
- large tabular/text data:
- HDF5(powerful but bloated and declining)
- Parquet(widespread and recommended)
- Feather(powered by Apache Arrow, up-and-coming)
- Try to use native Tensorflow and PyTorch dataset classes
- Object Storage
- An API over the filesystem
- GET PUT DELETE files to a service w/o worrying where tey are stored
- Database
- Online Transaction Processing(OLTP)
- Everything is actually in RAM, but software ensures that everything is logged to disk and never lost.
- Not for binary data!(store references instead)
- Postgress is a nice choice. Supports unstructured JSON.
- SQLite is perfect for small projects.
- Avoid NoSQL
- SQL and DataFrames
- Most data solutions use SQL. Some(like Databricks) use DataFrames.
- SQL is the standard interface for structured data.
- Pandas is the main DataFrame in the Python ecosystem.
- advice: be fluent in BOTH
- Data Lake
- Unstructured aggregation of data from multiple sources
- ELT: dump everything in, then transform for specific need later.
Data Processing
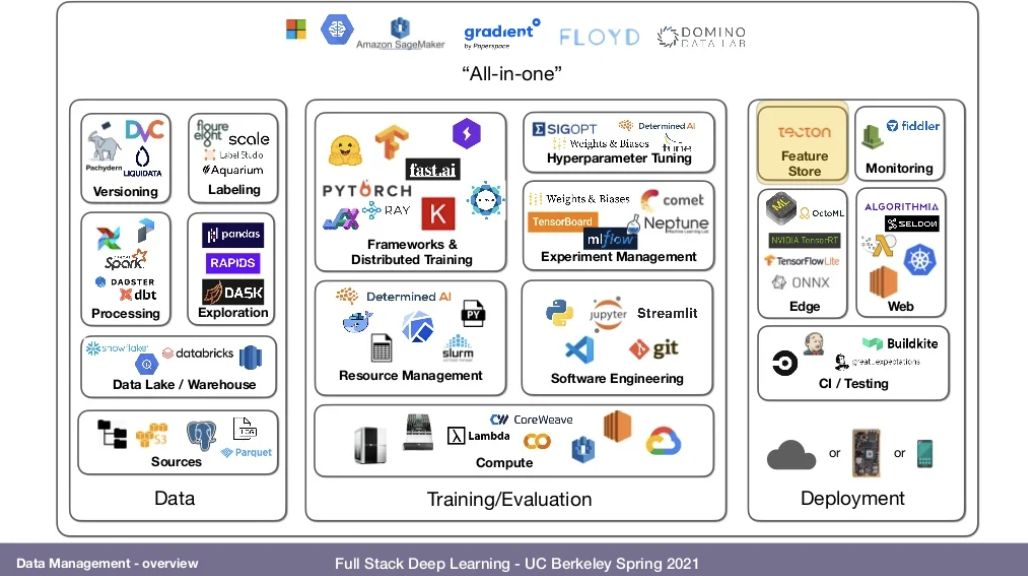
Feature Stores

Data Labeling
User interfaces
- Standard set of features
- bounding boxes, segmentations, keypoints, cuboids
- a set of applicable classes
- Training annotators is crucial
- And quality assurance is key!
Sources of labor

Service companies

- FigureEight
- Scale.ai
- Labelbox, etc.
Data Versioning
Level0: unversioned

Level1: versioned via snapshot at training time

Level2: versioend as a mix of assets and code

Level3: specialized data versioning solution

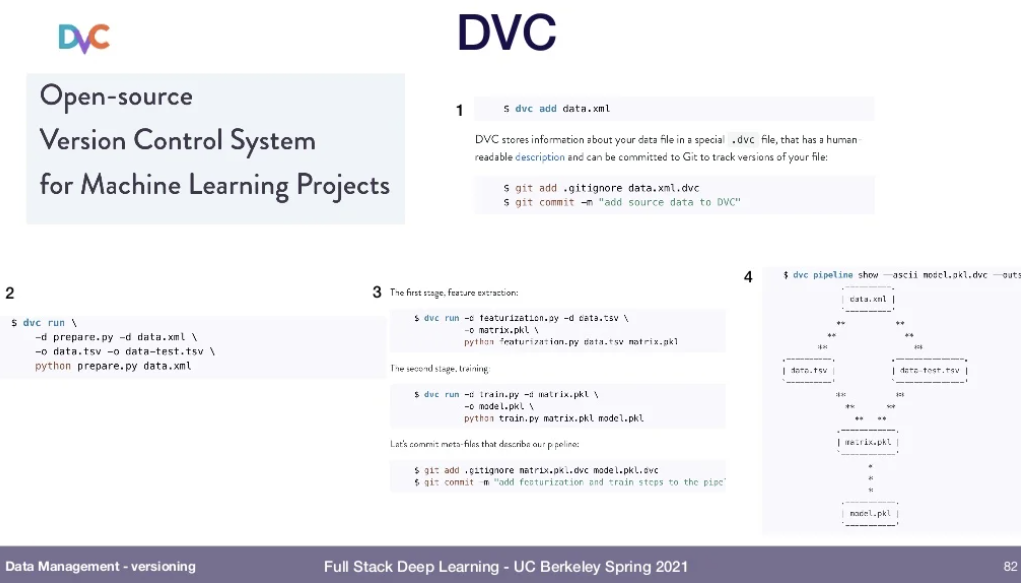
- DVC: Open-sources version control system for ML learning projects
'Deep Learning' 카테고리의 다른 글
| MLOps Infrastructure & Tooling (0) | 2023.02.15 |
|---|---|
| Transformers (0) | 2023.02.15 |
| Computer Vision (0) | 2023.02.15 |
| Deep Learning Fundamentals (0) | 2023.02.15 |
| [Colab] 코랩과 구글 드라이브 연동하기 (2) | 2023.01.02 |




댓글